Apache Kafka is a robust distributed streaming platform designed for high-throughput, low-latency data processing. By default, Kafka enforces a message size limit of 1 MB to maintain optimal performance and resource utilization. However, certain use cases necessitate the transmission of larger messages. This article explains some of the strategies to handle large messages in Kafka.
TL;DR
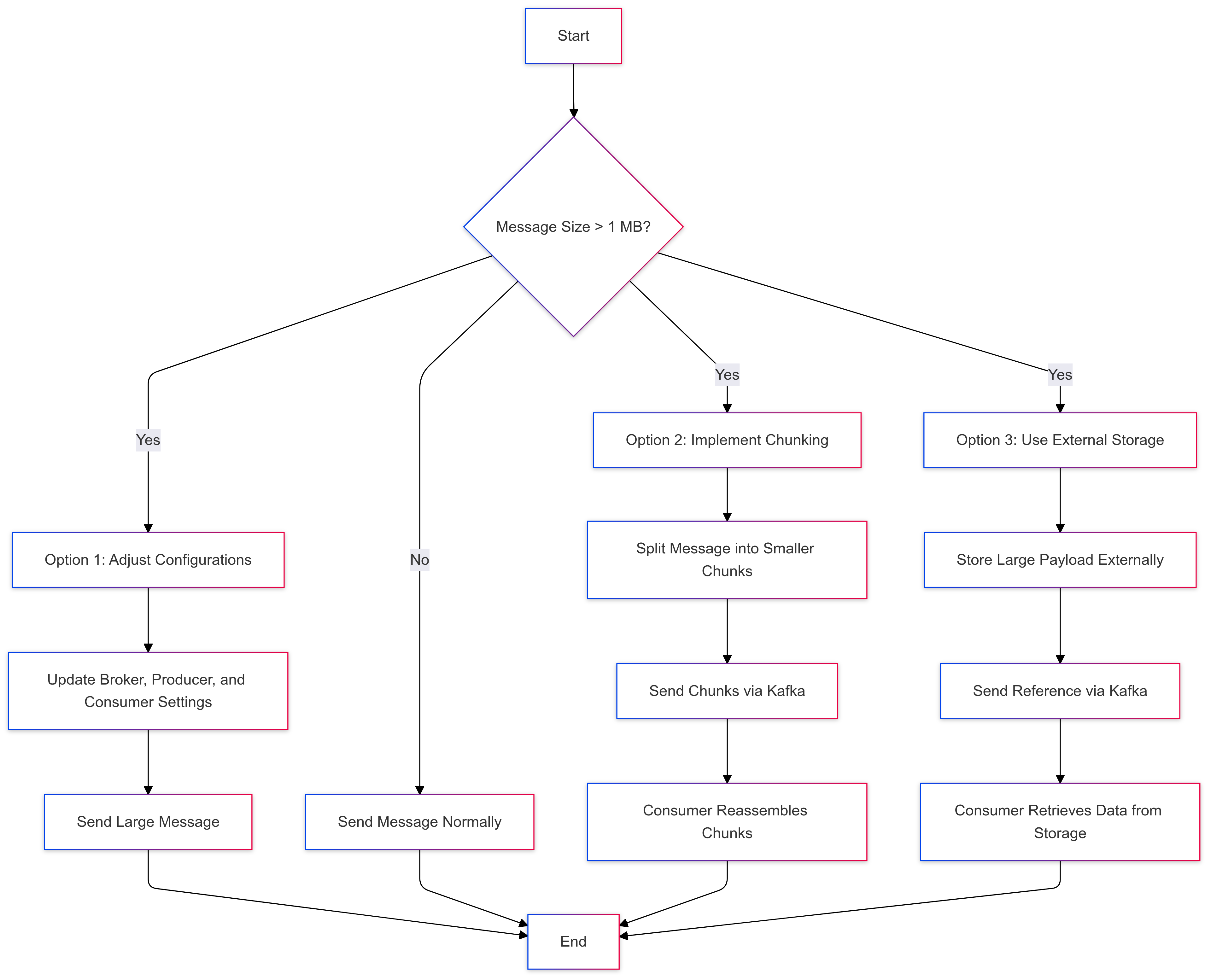
Kafka’s default message size limit is 1 MB, but larger messages can be accommodated by adjusting broker and producer configurations or by implementing alternative design patterns like message chunking or external storage references.
What is Kafka’s defualt Message Size Limit?
Kafka’s default maximum message size is set to 1 MB, controlled by the message.max.bytes parameter on the broker and the max.request.size parameter on the producer. This limitation is intentional, as larger messages can lead to increased memory usage, higher network latency, and potential performance degradation. Therefore, it’s crucial to assess whether increasing the message size aligns with your application’s requirements and Kafka’s design principles.
Handling Large Messages
Adjusting Configuration Parameters
To accommodate larger messages, you can modify the following configurations:
Broker Configuration:
Set the message.max.bytes parameter to a value that suits your needs. For example, to allow messages up to 10 MB:
message.max.bytes=10485760 Important:
The Broker-level configuration for setting the max message size is message.max.bytes. This setting can also be configured at the topic level with the max.message.bytes setting. Note that the two settings are named differently.
Producer Configuration:
Adjust the max.request.size parameter accordingly:
max.request.size=10485760 Consumer Configuration:
Ensure the consumer can handle larger messages by setting the fetch.max.bytes parameter:
fetch.max.bytes=10485760 It’s essential to apply these configurations uniformly across all relevant components to prevent message rejection due to size constraints.
Implementing Message Chunking
An alternative approach involves splitting large messages into smaller chunks that comply with Kafka’s default size limit. Each chunk is sent as an individual message, and the consumer reassembles them upon receipt. This method avoids the need to alter Kafka’s default settings and maintains system performance.
Considerations:
- Implement a consistent scheme for message segmentation and reassembly.
- Include metadata to track the sequence and integrity of message chunks.
- Handle potential message loss or duplication during transmission.
Implementing External Storage References
For exceedingly large payloads, it’s advisable to store the data in an external storage system (e.g., Amazon S3, HDFS) and transmit a reference or a metadata pointer to this data through Kafka. This strategy keeps Kafka messages lightweight and leverages specialized storage solutions for handling large files.
Workflow:
- Upload the large file to external storage.
- Generate a unique identifier, metadata or URL for the stored file.
- Send this identifier or metadata as a message via Kafka.
- Consumers retrieve the actual data from the external storage using the provided reference.
Best Practices
- Assess Necessity: Before increasing Kafka’s message size limit, evaluate whether it’s essential for your use case, considering potential performance implications.
- Monitor Performance: Keep track of system metrics to detect any adverse effects resulting from handling larger messages.
- Optimize Data: Compress messages to reduce their size before transmission, utilizing Kafka’s built-in compression options like gzip or snappy.
- Ensure Consistency: Apply configuration changes consistently across producers, brokers, and consumers to maintain system harmony.
References
- Apache Kafka Official Documentation: Configuration
- Confluent Blog: Apache Kafka Message Compression
- Baeldung: Send Large Messages With Kafka
- DZone: Processing Large Messages With Apache Kafka